Sqoop and Hive together form a powerful toolchain for performing analysis.
For example, there is data from a widget weblog (sales.log) in the following format
1,15,120 Any St.,Los Angeles,CA,90210,2010-08-01
3,4,120 Any St.,Los Angeles,CA,90210,2010-08-01
2,5,400 Some Pl.,Cupertino,CA,95014,2010-07-30
2,7,88 Mile Rd.,Manhattan,NY,10005,2010-07-18
Suppose we require data from both the sales.log and widget table to compute which zipcode is responsible for the most sales dollars.
3 step process
Create a hive table for sales.log
hive> CREATE TABLE sales (widget_id INT, qty INT, street STRING, city STRING, state >STRING, zip INT, sales_date STRING)
>ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
Ok
hive> LOAD DATA LOCAL INPATH "sales.log" INTO TABLE sales;
Ok
Sqoop can generate a hive table from an existing relational data-source.
% sqoop create-hive-table --connect jdbc:mysql://localhost/hadoopguide --table widgets --fields-terminated-by ','
Since we have already imported the widgets data into HDFS
hive> LOAD DATA LOCAL INPATH "widgets" INTO TABLE widgets;
Direct import into HIVE from Sqoop
The above 3-step process can be done directly using the below command
% Sqoop import --connect jdbc:mysql://localhost/hadoopguide --table widgets -m 1 --hive-import
Compute the most profitable zip-code by querying hive tables
hive>CREATE TABLE zip_profits (zip INT, profit DOUBLE)
OK
hive>INSERT OVERWRITE TABLE zip_profits
SELECT s.zip, sum(w.price * s.qty) AS profit
FROM sales s JOIN widgets w
ON s.widget_id=w.id
GROUP BY s.zip
hive> SELECT * FROM zip_profits ORDER BY profit DESC;
OK
90210 403.71
10005 28.0
95014 20.0
Importing Large Objects
Depending upon large data objects are textual or binary, they are stored as CLOB or BLOB fields in database.
Sqoop can extract large objects from dbs and store them in HDFS.
Typically data is stored on disk like below. If large objects are also stored in the similar fashion, it will have adverse affect on performance
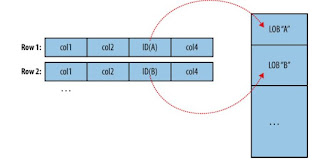
 Hence, generally databases store only a reference to this Large objects as shown below.
Hence, generally databases store only a reference to this Large objects as shown below.
For example, there is data from a widget weblog (sales.log) in the following format
1,15,120 Any St.,Los Angeles,CA,90210,2010-08-01
3,4,120 Any St.,Los Angeles,CA,90210,2010-08-01
2,5,400 Some Pl.,Cupertino,CA,95014,2010-07-30
2,7,88 Mile Rd.,Manhattan,NY,10005,2010-07-18
Suppose we require data from both the sales.log and widget table to compute which zipcode is responsible for the most sales dollars.
3 step process
Create a hive table for sales.log
hive> CREATE TABLE sales (widget_id INT, qty INT, street STRING, city STRING, state >STRING, zip INT, sales_date STRING)
>ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
Ok
hive> LOAD DATA LOCAL INPATH "sales.log" INTO TABLE sales;
Ok
Sqoop can generate a hive table from an existing relational data-source.
% sqoop create-hive-table --connect jdbc:mysql://localhost/hadoopguide --table widgets --fields-terminated-by ','
Since we have already imported the widgets data into HDFS
hive> LOAD DATA LOCAL INPATH "widgets" INTO TABLE widgets;
Direct import into HIVE from Sqoop
The above 3-step process can be done directly using the below command
% Sqoop import --connect jdbc:mysql://localhost/hadoopguide --table widgets -m 1 --hive-import
Compute the most profitable zip-code by querying hive tables
hive>CREATE TABLE zip_profits (zip INT, profit DOUBLE)
OK
hive>INSERT OVERWRITE TABLE zip_profits
SELECT s.zip, sum(w.price * s.qty) AS profit
FROM sales s JOIN widgets w
ON s.widget_id=w.id
GROUP BY s.zip
hive> SELECT * FROM zip_profits ORDER BY profit DESC;
OK
90210 403.71
10005 28.0
95014 20.0
Importing Large Objects
Depending upon large data objects are textual or binary, they are stored as CLOB or BLOB fields in database.
Sqoop can extract large objects from dbs and store them in HDFS.
Typically data is stored on disk like below. If large objects are also stored in the similar fashion, it will have adverse affect on performance


MapReduce typically materializes in memory every record before it passes to the mapper. Depending upon the size of the object, full materialization in memory may be impossible.
To overcome the above, Sqoop stores imported large objects in a separate file called a LobFile.
> Each record in a LobFile can store single large object (64-bit address space is used)
> This file format allows clients to hold a reference to the record without accessing its contents
> When content is access using java.io.Stream oor java.io.Reader
When a record is imported, the normal fields will be materialized together along with a reference to the LogFile where the CLOB or BLOB column is stored.
E.g suppose our widget table contains a CLOB field called schematic containing the exact schema diagram for each widget
2,gizmo,4.00,2009-11-30,4,null,externalLob(1f,lobfile0,110,50011714)
1f - file format
logfile0 - filename
110 - offset
50011714 - length inside the file
When working with record, Widget.getSchematic() will returrn a type of object CLOBRef (referencing the schematic column but not actual content)
The CLOBRef.getDataStream method actually opens the LobFile and returns an InputStream allowing to access its contents
The ClobRef and BlobRef classes caches references to underlying to LobFiles within a Map task.
No comments:
Post a Comment